DjangoなどのWebフレームワークにはマイグレーションという機能が搭載されています。ですがこのマイグレーションという機能の必要性が分かりにくい(いまいちピンときていない人がけっこう多い)ので背景を踏まえて説明します。
Webフレームワークのマイグレーション機能はDjangoやRailsに付属している機能です。
そもそもDBマイグレーションは、すでに本番環境等にリリースされたデータベースを破壊せずに、アプリ側で使いたい新しいテーブルやカラムを追加(もしくは変更、削除)することです。毎回データベースをすべて削除して1から作り直してしまえば「DBマイグレーション」は考えなくて済みますが、そうするとユーザー情報や過去に書いた記事などがすべて消えてしまいます。
そういった問題を解決するため、Webフレームワークなどが「マイグレーション」という機能を提供しています。ですが便利すぎるゆえ、逆になぜ必要なのかも分かりにくくなっています。フレームワークのモデルを書き換えると、なぜかマイグレーションファイルを作ってマイグレーションを実行しろと言われますね。マイグレーションファイルが作れなかったり、なぜかデータベースに適応できなかったりトラブルが起こったりもします。そこで…
マイグレーション、要らないのでは?
消したほうが楽なのでは?
など言われてしまうのですが、そうではありません。めちゃくちゃ便利ですごい機能なんです。
この記事ではマイグレーション機能がない世界でのデータベースの運用を説明し、改めてマイグレーション機能の必要性を理解しようと思います。
マイグレーション機能がない世界を考えてみましょう。
まずモデルとしてはこういったユーザーの情報を考えます。
class User(models.Model):
name = models.CharField(...)
無事にアプリを本番リリースし、以下のようなデータベースが動いていると考えましょう。ユーザーのテーブルがあり、IDとユーザー名が管理されています(IDフィールドは勝手に作られます)。
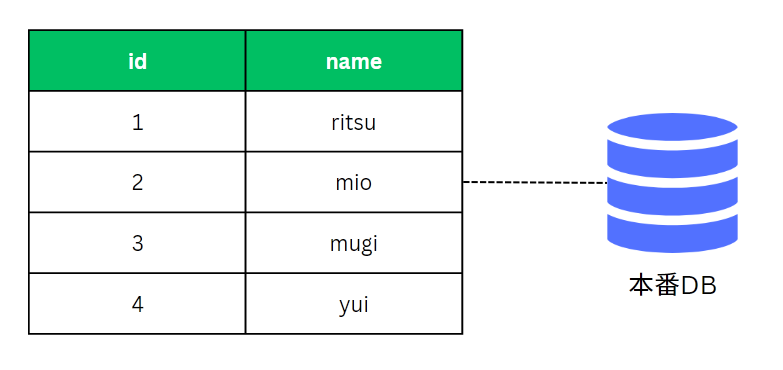
このテーブルがアプリ上のUserモデルに対応しているわけですね。
ここで新機能として「自己紹介欄」を追加したくなりました。Djangoのモデルで言うと、この2つ目のフィールドを追加した状態にします。
class User(models.Model):
name = models.CharField(...)
bio = models.CharField(...)
この場合、最終的には以下のようなテーブルがデータベース上に必要となります。最初は bio に何も入っていなくても良いですが、ユーザーが好きに自分のことを書けるようにしたいわけです。
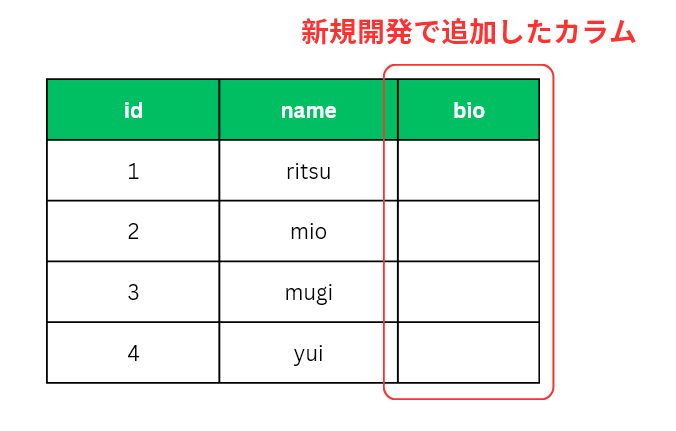
さてプログラム的には bio というカラム(モデルのbioフィールド)を利用するよう書き換えたわけですが、今すでに存在しているデータベースには bio というカラム(フィールド)がありません。
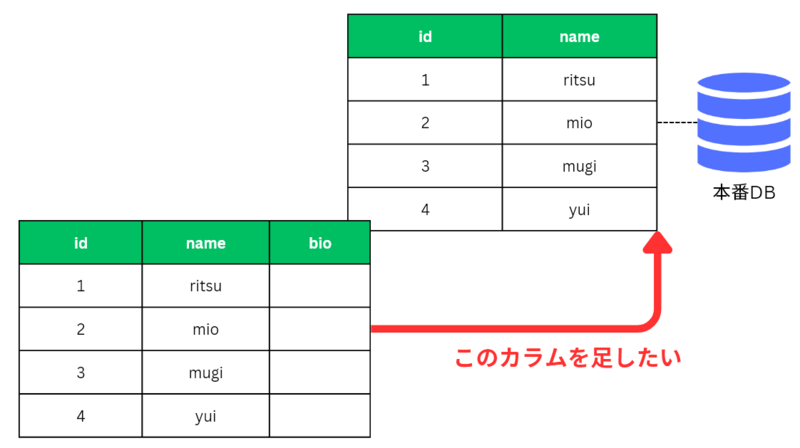
プログラム上は bio を使うように書き換えたのに、本番データベースにはそのカラムがないわけです。これは困りました。データベースを一旦削除して再度作り直すと、せっかく集めたユーザー情報も消えてしまいます。
ここで以下の3点がポイントになります:
- データベース(RDB)側のテーブル定義を変更しないといけない
- プログラム上の「Userモデル」等を書き換えても自動的にデータベースは変わらない
- データベースを変更しないままアプリが
bioを使おうとするとエラーになる
これはMySQLやPostgreSQLなどのリレーショナルデータベースがテーブルの定義(データ構造)をしっかり決めてデータを管理するデータベースだからです。アプリ側で bio というデータを使いたいとなった以上、データベースに変更が必要です。
データベースにカラムを追加するにはどうすれば良いでしょうか? 正解は ALTER TABLE ... ADD とカラムを追加するSQLをデータベースに実行することです。
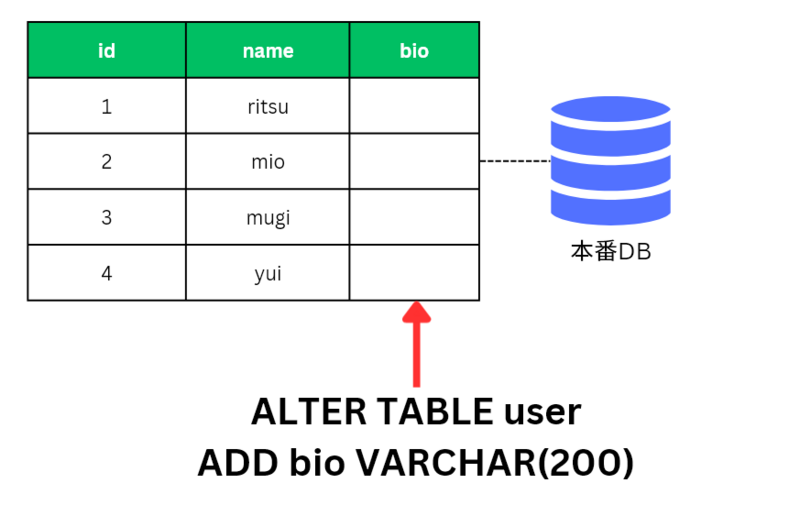
このSQLを実行するとデータベース上に bio カラムが作られ、bio を使うアプリをリリースしても正常に動作するというわけです。これがDBマイグレーションの基本的な考え方です。
さてこの ALTER TABLE ... ADD のSQLを実行すべきなわけですが、アプリを書き換えたタイミングでこのSQLを用意しておく必要がありますね。
class User(models.Model):
name = models.CharField(...)
bio = models.CharField(...)
そこでこの変更を加味して、SQLのファイルを作っておくことにしました。こうすれば他の人が見ても「リリース時にSQLの実行が必要なんだな」と分かりますし、自分でも思い出せて便利ですね。
0002_user_bio.sql というファイル名で作っておきましょう。
ALTER TABLE user
ADD bio VARCHAR(200) DEFAULT '' NOT NULL;
このSQLを migrations というディレクトリーに入れておくことにしました。ついでに、データベースを作る際に実行したSQLも 0001_initial.sql として置いておきましょう。
migrations/
- 0001_initial.sql
- 0002_user_bio.sql
これでOKです!
こうしてデータベースの変更をSQLとして管理し、Webサービスを運営していくことができました。
自前の管理で起こり得るトラブルは何?
実際に昔はWebフレームワークのDjangoにはマイグレーション機能がなく、このようにSQLを保存して管理したりしていました。SQLで管理していれば良いほうで、その場その場でSQLを書いて間違えてしまったりもありました。
どういった問題が起こるのでしょうか。こういったことが考えられます:
- どこまでマイグレーション用のSQLを実行したか分からなくなる
- モデル(テーブル)の変更内容と違うSQLを書いてしまう
- 書くべきSQLがデータベースの種類ごとに少しずつ違う
- そもそもDBマイグレーションを管理しておらず各データベースの状態が分からなくなる
昔はけっこうこういった問題があり、うんうんうなりながら何とかしたわけです。
そこで登場するのがマイグレーションという機能です。Djangoでは先に South というマイグレーション用のツールが登場し、一般的に使われるようになりました。その後、このSouthの開発者を中心にDjangoにマイグレーションという機能が組み込まれていきました。
マイグレーション機能のポイントは以下です:
- モデルの変更を検知して、自動的にマイグレーションファイルを作成する
- マイグレーションファイルからSQLが作られ、データベースに変更が適応される
- データベースごとにどこまでマイグレーションを実行したか履歴を管理する
さきほどSQLで管理していた migrations/0002_user_bio.sql などは migrations/0002_user_bio.py というものに置き換わります。ですが内容はまったく同じです。このマイグレーションファイルを自動で生成してくれるので、自分で適応すべき変更差分を書く必要がありません。また、使っているデータベースの種類に応じて、SQLも適切に書き換えてくれます(SQLを直接生成しないのはこのため)。
またDjangoのマイグレーション機能はデータベース自体に「どこまでマイグレーションを実行したか」の履歴を保存しておいてくれるので、 python manage.py migrate と実行するだけでデータベースごとに必要な変更が取り込まれます。django_migrations という自動で作られるテーブルで管理されており、マイグレーションを実行したタイミングで適応済みの履歴も自動で更新されます。
つまり、SQLで管理していたような作業をすべて自動でまかなってくれるということです。Djangoではこういった仕事が必要となることを見越して、機能として提供しています。
おさらいするとこうなります:
ここでDjangoが提供しているコマンドを見てみましょう。先ほどSQLで管理していた例を思い出しながら、各コマンドが何をしてくれているかを理解しましょう。
makemigrations
モデルの変更を検知してマイグレーションファイルを作成します。マイグレーションファイルは上記したような「変更を管理するSQL」と似たものです。
たとえばユーザーに bio のフィールドを足すと、 migrations/0002_user_bio.py のようなファイルが生成され、これが ALTER TABLE ... ADD bio ... というSQLに相当します。
migrate
DBマイグレーションを実行します。対象のデータベースからまだ適応されていないマイグレーションファイルを検知して、マイグレーションファイルからSQLを生成し、データベースにSQLを適応します。
migrate --plan
現在対象のデータベースに対して、これから実行されるであろうマイグレーションの内容を表示してくれます。
migrate --fake
マイグレーションの変更を適応せず、実行履歴のみ「適応したこと」として更新します。すでに別の方法で変更が取り込まれている場合などに実行します。
showmigrations
管理されているすべてのマイグレーションと、どこまで適応されたかの状況を表示します。
sqlmigrate
指定されたマイグレーションファイルをSQLにして表示します。SQLで管理する例であげていたような ALTER TABLE ... ADD などのSQLです。対象になっているデータベースに応じてSQLの方言もあわせます。
squashmigrations
指定された複数のマイグレーションを1つにまとめます。まだ適応されていないマイグレーションが複数ある場合に、このまとめられたマイグレーションを実行するだけで済むようにします。
他にも湧いてくるであろう疑問と答え
話としてはだいたい終わりました。
ここで、これまでの説明を踏まえて湧いてくるであろう疑問に答えておきます:
- まだ本番データベースなどを管理していないのに
migrate しろと言われるのはなぜ?
- ローカルで開発中に使っているデータベース(SQLite)などの更新に必要です
- 本番にリリースしていない場合、マイグレーションファイルは必要?要らなくない?
- ローカルのDBの管理もあるので使っておくと良いです
- 慣れないうちはマイグレーションファイルを下手に削除したりいじったりしないほうが無難です
makemigrations したときに one-off default どうこうと質問されるのは何?
- カラムを追加するときに既存DBでの値をどうするかを聞かれます
- フィールドにデフォルト値等があればその値になりますが、ない場合は一時的なデフォルト値が必要と言われています
- 今回の
bio であればデフォルトで空文字やNULL可能としておけば自動で空文字やNULLが入れられます
- 開発中にマイグレーションファイルが大量にできてしまいます
squashmigrationsコマンドでまとめることができます- 慣れていれば、開発ブランチで適応された変更をまとめたマイグレーションに自分で作り直すのも可能です(ローカルのSQLiteの変更履歴も操作が必要です)
- ファイルの数が極端に多くなる場合は、もう少しモデルの設計をじっくり考えてから開発したほうが良いかも
- 本番データベースにマイグレーションを適応するタイミングはどうすれば良い?
おわりに
今回はざっくりとDBマイグレーションについてとWebフレームワーク等が提供するマイグレーション機能の意味を説明しました。Webフレームワークやツールが便利になるごとに、なぜそれが必要なのかは逆に分かりにくくなってしまいます。ですがこうして背景を一つひとつ理解していくことで、その意味をお伝えできると嬉しいです。
執筆:清原 弘貴 (@hirokiky)、レビュー:清原 弘貴 (@hirokiky)
(Shodoで執筆されました)